Teams5 updates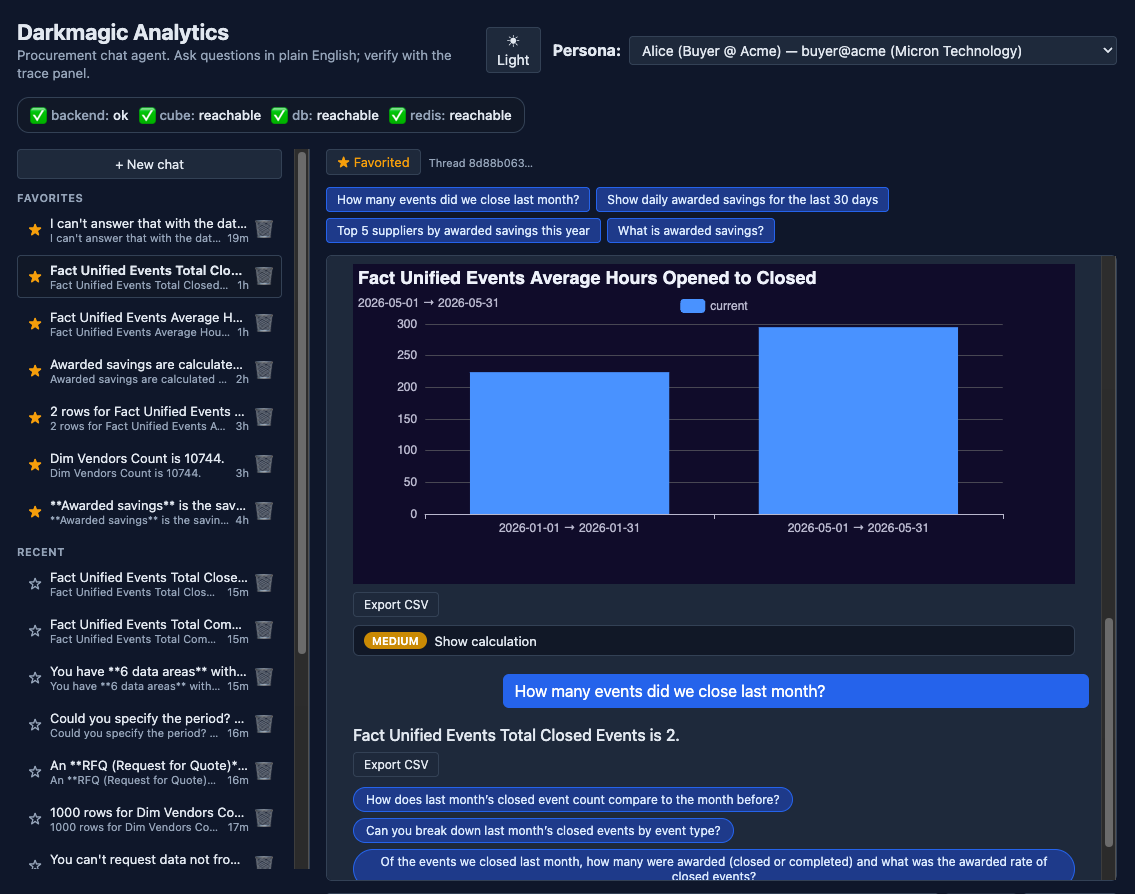









Heroes of AI and Magic
Analytics AgentAR
Aliaksei Ramanau Final
May 11, 09:49 PM
# darkmagic-analytics-agent
Ask Fairmarkit data a question in plain English. Get a chart, a number, and the math behind it.
We built an analytics agent that turns natural-language procurement questions into validated Cube-backed answers — with charts, CSV export, friendly errors, a "show me how" trace panel, and a dark theme that should make everyone Linuxoid happy.
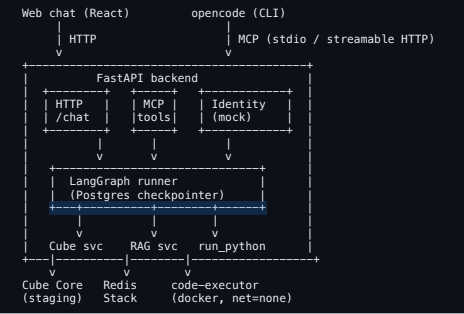
#What's under the hood
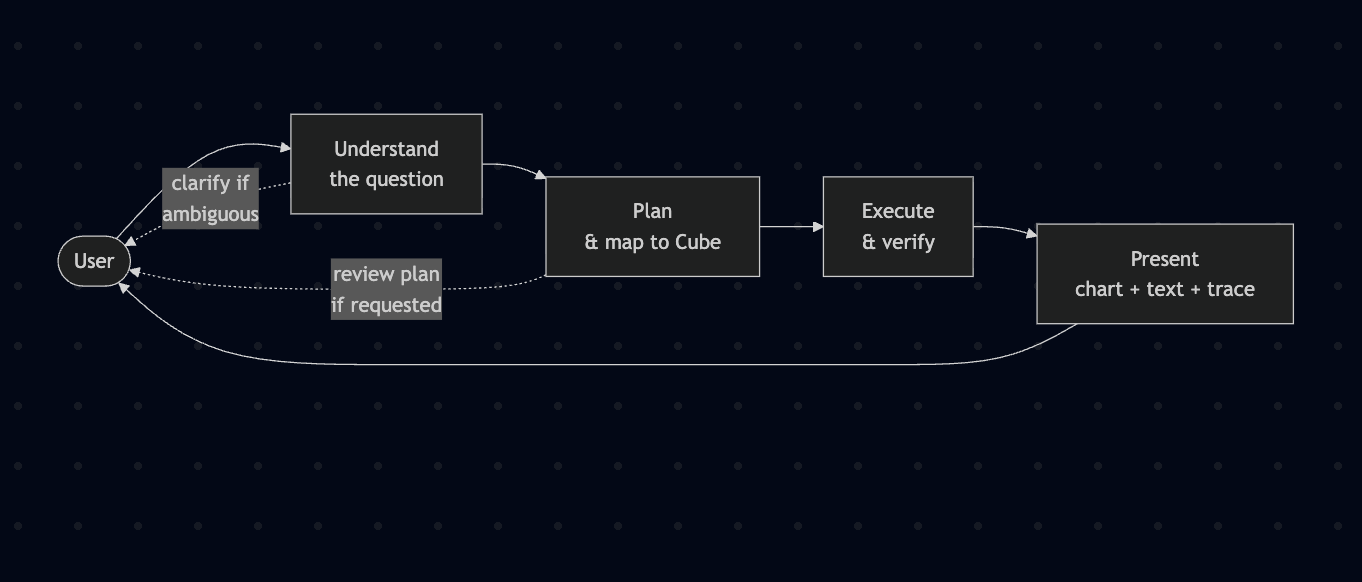
A LangGraph plan-and-execute pipeline (~20 specialized nodes) sits on top of the existing Cube semantic layer. Every number on screen is the output of a Cube query that was generated by the agent, validated against Cube metadata, and executed deterministically - no free-form SQL, no hallucinated metrics[eventually in prod ;) ]. A second cheap-LLM "mapper critique" node catches roughly 30% of wrong-metric mistakes before they hit Cube. The verifier flags time-series anomalies with a z-score gate, so the presenter can call them out instead of glossing over them.
# Resources
* Git repo: https://gitlab.fmdev.io/analytics/darkmagic-analytics-agent
* Docs: https://gitlab.fmdev.io/analytics/darkmagic-analytics-agent/-/tree/master/docs?ref_type=heads
* Pitch presentation with more details: https://docs.google.com/presentation/d/1qwRq-kqsV3RyeafJNboilSmTDEngjZ-hg4OOcIPE_ho/edit?slide=id.g3e0f0a7a62f_0_72#slide=id.g3e0f0a7a62f_0_72
* More screenshots: https://drive.google.com/drive/folders/17NGUFwXQSpkjleUxiw-4QJM4Y_RuHHDV
# Team & thanks
Engineered by Alex Ramanau + a squad of AI agents(claudecode, opencode) with direct help from Yaugeniy Shalkevich and Marceli Adamzyk, and sharp feedback from Viktor and Andrew.
Special kudos to Yaugeniy Shalkevich for explaining in simple words complex domain-specific problems.
?
AR
Aliaksei Ramanau
May 11, 11:14 AM
# Weekend — Stabilize the trunk, branch out for intelligence
We went into the weekend with a working agent and a clear feedback:
**don't add breadth — add trust and depth.** Two days later we have a
sturdier trunk *and* two intelligence prototypes built in parallel on a
separate VM via agentic engineering.
## Stabilization (master)
**Web-search / procurement branch — finalized.** HITL flow hardened against
the edge cases that bit us on Day 3; full e2e green. Multiple small fixes
applied directly from what e2e tests surfaced — exactly the loop the CTO
asked for.
**Per-turn chat checkpoint.** New migration `0004_chat_pending_checkpoint`
+ 232-line test suite. The agent now distinguishes "user repeated the same
question" from "user asked something new," and resumes from the right
LangGraph state. Removes a whole class of stale-context bugs.
**FE that fails politely.** When Cube goes away, the user gets a clear
status panel and an actionable error - not a JavaScript stack trace. Small
change, big "this is a real product" signal.
**Project renamed** to `darkmagic-analytics-agent`.
Module paths, Prometheus, Docker, lockfiles — all green after the rename.
## Two intelligence prototypes (parallel branches, VM-hosted)
To not block the master trunk, the two intelligence prototypes were built
on a separate VMs, using **opencode + OpenAI GPT-5.5** and Claude Code + Opus 4.7.
Each prototype followed its own pre-written spec (Round 13) and landed in its own
feature branch so they can be reviewed, merged, or shelved independently.
### Branch 1 - Verification & self-correction
[`feature/13-anomaly-zscore-prototype+14-mapper-critique-prototype`](https://github.com)
- **Z-score outlier check** ([spec 13](spec/13-anomaly-zscore-prototype.md))
- verifier flags time-series points that deviate >3σ from the local
window, so the presenter can call them out instead of glossing over them.
133-line test suite.
- **Mapper self-critique node** ([spec 14](spec/14-mapper-critique-prototype.md))
- cheap-LLM plausibility gate between `cube_mapper` and `execute`.
Catches wrong-metric / missing-filter mistakes and triggers a single
bounded retry. 131-line node, 283-line test suite. Projected to auto-correct
~30% of mapping errors before they hit Cube.
### Branch 2 - Retrieval & best-practices grounding
[`feature/spec-09-plus-10-bestpractices-and-followups`](https://github.com)
- **Few-shot retrieval + anomaly flagging** ([spec 9](spec/09-fewshot-and-anomaly.md))
The mapper now retrieves similar past Q→Cube-query
pairs from a small curated index before generating a new query.
- **Procurement best-practices RAG corpus.** 19 hand-curated markdown
documents across `savings/`, `cycle-time/`, `engagement/`, `governance/`
- the kind of institutional knowledge that turns a generic SQL bot into
a procurement-aware advisor.
- **Engagement response-rate suggester**, refined after domain-expert
feedback from Marceli - thresholds now match how FM customers actually
read the metric.
- **Comprehensible QA scenarios** documenting the expected best-practices
behavior, so the eval set can prove the RAG is actually moving the
answers in the right direction.
## By the numbers
14 commits across 4 branches · 267 files · +5.4k / −0.8k lines ·
2 new prototypes shipped behind feature branches ·
19-doc procurement RAG corpus · 5 new test files (~1k lines of new tests).
## Today's we're on the final stretch (Day 5)
1. **UX-flow polish + last-mile bug fixes** - every demo claim shows
green on the real product.
2. **Sharpen the eval against Micron Technology staging data** -
anonymized data, optimize the **North Star metric: % of natural-language
questions answered correctly.**
3. **Pitch + demo.** get out of the comfort zone and prepare comprehensible pitch + demo.
## Meanwhile, in a parallel universe
Two production streams are moving alongside it:
- **AWS production deployment of `ai-analytics` + `platform-analytics`** -
configs finalized, deployment pipeline being driven through to prod.
- **Analytics 2.0 → Azure uat/staging** - Cube configuration verified,
release being prepped for uat/staging rollout.
Same brain, different terminals. The "fast software engineering" claim
isn't theoretical - it's how today is actually being scheduled.
---
**Fun fact.** In parallel with shipping features, the same engineers also
managed to grill spicy chicken wings on the bank of the Vistula. Turns
out spec-driven development frees up enough cycles for proper smoke
testing — the literal kind. 🔥🍗
VK
Viktar Kushch
May 11, 02:46 PM
?
AR
Aliaksei Ramanau
May 9, 03:46 PM
# Day 3 — From "looks impressive" to "we can prove it works"
We started Day 3 with a working vertical slice. We end it having absorbed
honest and valuable feedback from Viktor/Andrew, sharpened the demo posture, and shipped a chunk of real product feel — without splitting focus.
## The pivot — CTO / VP of Engineering feedback
A mid-hackathon sync delivered the signal we needed: *"anyone can vibe-code
a chat in a week."* Two paths to maturity — polished UX **or** depth of
reasoning. Pick one. Lean in.
We picked **both**. Chat need to be useful and be prototype for new UX flows - data
exporting and become just a useful everyday tool.
## What we shipped
**Chat lifecycle that feels like a real product.** List, delete, **undo**,
and **pinned/favorite chats** with a partial-index migration. UNDO is the
single most requested missing piece from FM's current AI Kit chat — it now
exists.
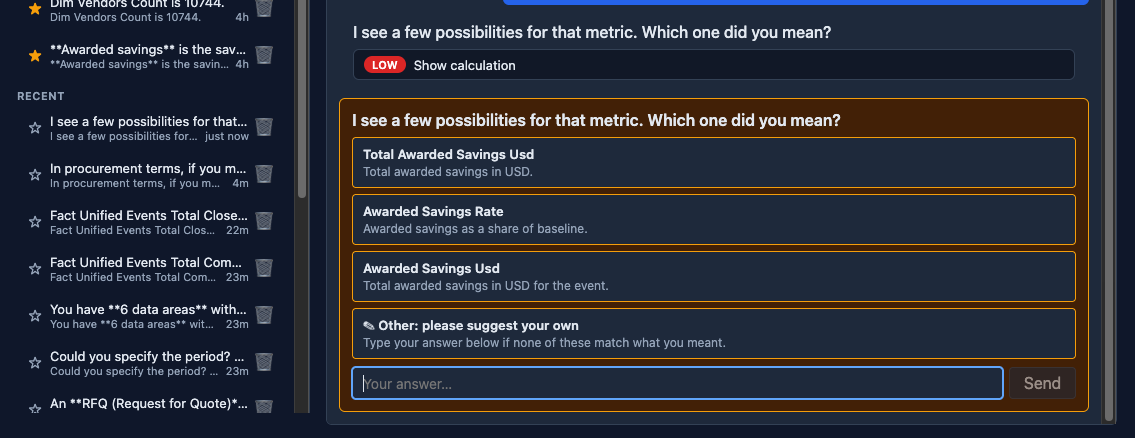
**HITL that doesn't look like a wall of text.** Ambiguity questions are
now structured choices (3 + "Other"). Fixed the broken metrics-ambiguity
flow that snuck in late on Day 2. +289 lines of clarification-loop tests
pin the behavior.
**Smarter metrics discovery.** *"What can I ask?"* now returns a curated,
role-aware catalogue — not a 200-item dump. 216-line node + 290-line test
suite.
**Cross-tenant requests handled explicitly.** When a buyer at Tenant A
asks about Tenant B's data, the agent refuses by name and emits an audit
event — no more silent empty results. New permission cases in the eval set.
**Spec depth — six micro-specs to push intelligence.** Round 13 of the
spec process produced concrete, ready-to-implement prototypes:
mapper self-critique (E001.C2), few-shot retrieval, anomaly detection,
presenter heuristics, suggested follow-ups, best-practices RAG.
**Isolation-hardening spec.** `spec/15-isolation-hardening.md`
— 521 lines closing three near-miss gaps surfaced by an internal security
review (multi-cube tenant filter, silent mapping fallback, LLM-supplied
tenant filter rejection).
## This is *not* vibe-coding
What we're really doing: re-implementing FM's existing AI Kit chat (from
`ai-analytics`) with an improved user flow and advanced agentic
engineering — using **spec-driven agentic development** as the discipline.
That discipline is recognizably *software engineering*, not "talk to an
LLM until something works":
- **16 committed specs** in `docs/spec/` — each hand-offable to any
engineer or coding agent.
- **60+ logged decisions** in
`context/005-decisions-log.md.
traceable across 13 rounds of design conversation.
- **Audit chain:** every commit references a spec; every spec references
a round; every round references the original brief.
- Reasoning happens **before** code, in writing, reviewable by humans.
Disagreement is resolved at the spec layer where it's cheap — not at
merge time where it's expensive.
- The "agentic" part is that drafts of specs and code are produced by an
LLM. The senior-engineer judgment — what to spec, what to cut, what to
verify — stays human.
**It's just software engineering in 2026. Done fast.**
## By the numbers
12 commits · 72 files · +5.2k / −0.2k lines · 1 new domain spec ·
1 isolation spec · 6 ready-to-implement micro-spec prototypes.
## Weekend focus
1. **End-to-end flow polish & testing** — every demo claim has a green
path on staging, top to bottom.
2. **Golden dataset, sharpened against real customer data** —
consolidate to 15–20 branch-diverse cases, all
running on staging Cube. The eval-pass number drives the demo's North
Star slide.
3. Implementing a couple of prototypes to increase intelligence of the AI Agent.
4. **Stability verification + bug fixes** — repeat the eval run, fix
what breaks, chase the number until it holds steady across runs.
VK
Viktar Kushch
May 9, 04:13 PM
AT
Andrey Timonin
May 10, 04:34 PM
?
AR
Aliaksei Ramanau
May 8, 08:14 AM
# Day 2 — From skeleton to a real conversation
We started Day 2 with bones. We end it with a procurement agent that
**talks back, remembers, and refuses to lie about numbers.**
## Highlights
**Real domain, not toy data.** Vendored the production Cube schema (18.8k lines,
synced offline so the agent can run with no live Cube) and shipped two new cubes:
`dim_vendors` and `fact_unified_responses` (354 lines of facts and measures).
The agent now answers against the same model our analytics team ships to our real customer -
Micron technology.
**Multi-turn intake that actually intakes.** Conversation-aware ambiguity check
with inline metadata lookup — the agent asks the *right* follow-up instead of
shrugging.
**"Last quarter," "this fiscal year," "Q3" — all just work.** New
`timeframe.py` translates natural-language date phrases into Cube time
dimensions.
**Golden dataset is live.** 614-line PM domain notes + 48 new core-golden
cases. We can now measure the agent getting smarter — or dumber — instead of
guessing.
**End-to-end coverage.** 608 lines of Playwright + a 236-line responses-cube
test suite. No more vibes-driven shipping.
**The UI grew up.** Pretty markdown rendering in chat, a real dark theme with
a switcher, CSV export from any answer. Pinned/favorite chats half-landed
(migration + repo done, FE polish in flight).
## By the numbers
13 commits · 112 files · +22.8k / −4.5k lines · 4 new test suites, all green
## Where we are
The simple path is no longer a demo trick — it's a product loop:
**ask → clarify → query the real warehouse → render → export.**
Day 3 unlocks the complex path + the human-in-the-loop escape hatch, and
we start hammering it with the eval harness.
------------------------------------------------
P.S.
* Uploading of pictures still doesn't work to me, but here is the link to my hacking env:
https://drive.google.com/file/d/1DKdzSuacLaspeYM2n_dT4oIBx6WnTdeo/view?usp=drive_link
* A humble screenshot from the magic Analytics chat:
https://drive.google.com/file/d/1Lq63QuTF9uQdqUtrVpWBXbKjEArU0oMH/view?usp=sharing
(I'll provide later, chat is broken due to disconnection from VPN. To post this update I need to be painfully disconnected from Staging Cube :] )
* 0.66l of coffee, 1.5l of tea, 1 glass of Cyprus wine consumed - hope I won't disqualified for doping :)
AT
Andrey Timonin
May 8, 01:05 PM
AL
Aliaksandr Layuk
May 8, 03:07 PM
?
AR
Aliaksei Ramanau
May 6, 08:13 PM
Quick update from *Heroes of AI and Magic*:
What's done:
* prepare working place for hacking in the new homeoffice
* load extra product context form company expert (kudos to Yauheniy Shalkevich)
* setup repo and init project context
* prepared HLD and verified by human and one more LLM
* setup team of AI agents and started implementation
P.S. Fun facts:
* consumed 2.33 cups of coffee and 0.76l of beer
* spilled 0.66 cups to the desk (fortunately, no serios damage)
* consumed Claude Code limits in 1.5 hour, requested Premiums seat capability (thanks to Andrew Timonin for immediate addressing the problem)
Stay tuned :)
AL
Aliaksandr Layuk
May 8, 03:05 PM
DA
Denis Atyasov
May 10, 08:54 PM
?